Creation of stable water-free antibody based protein liquids
Communications Materials 2021
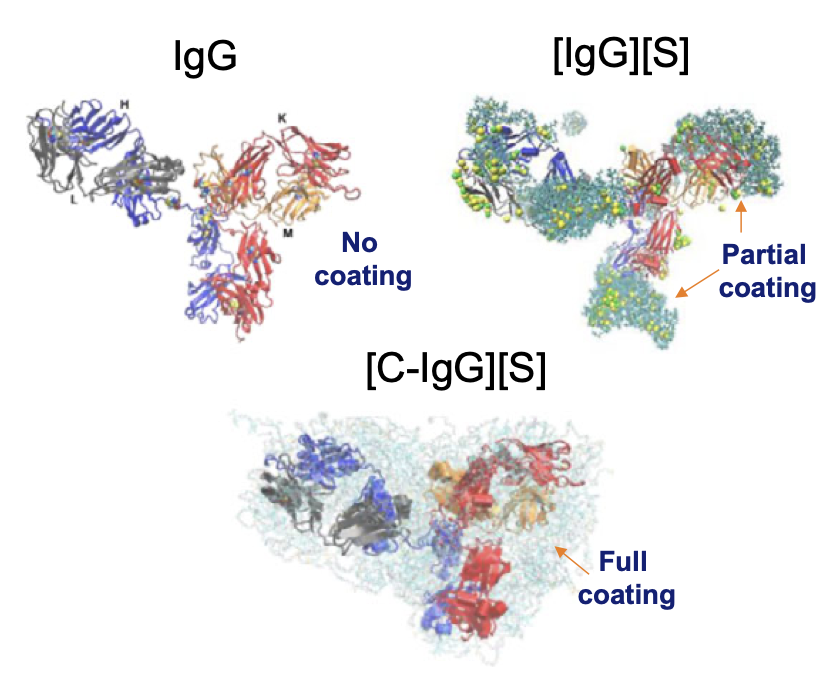
Extensive molecular dynamics simulations are carried out under extreme conditions to investigate the mechanism for creation of stable water-free antibody based protein liquids. … Read more →
Gamma estimator of Jarzynski equality for recovering binding energies from noisy dynamic data sets
Nature Communications. 2020
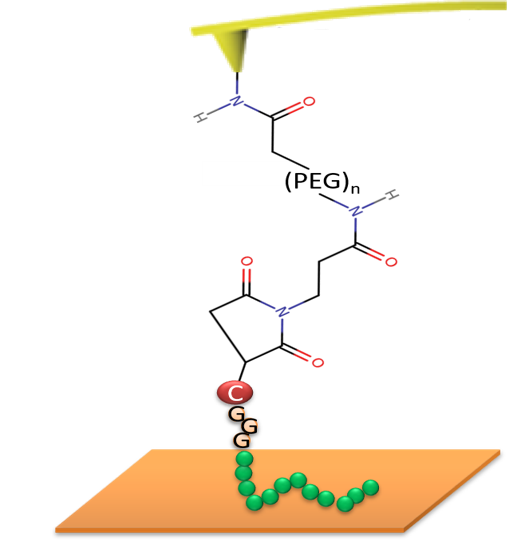
A novel statistical method is employed to calcuate binding free energy of a single peptide on gold surface from data collected from single molecule pulling experiments. … Read more →
Peptide interactions with zigzag edges in graphene.
Communications Materials 2021
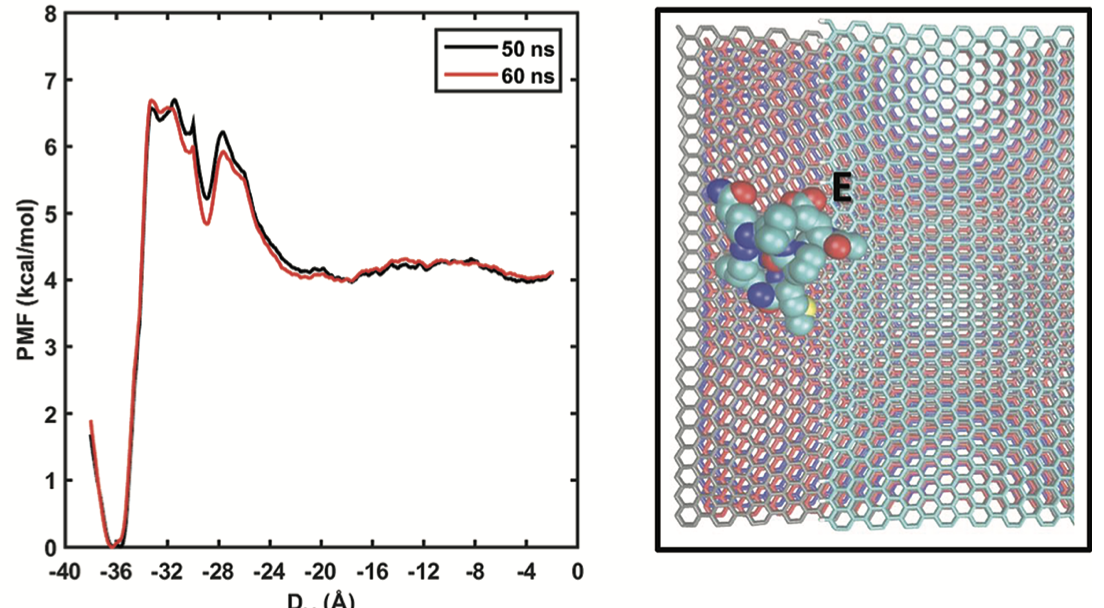
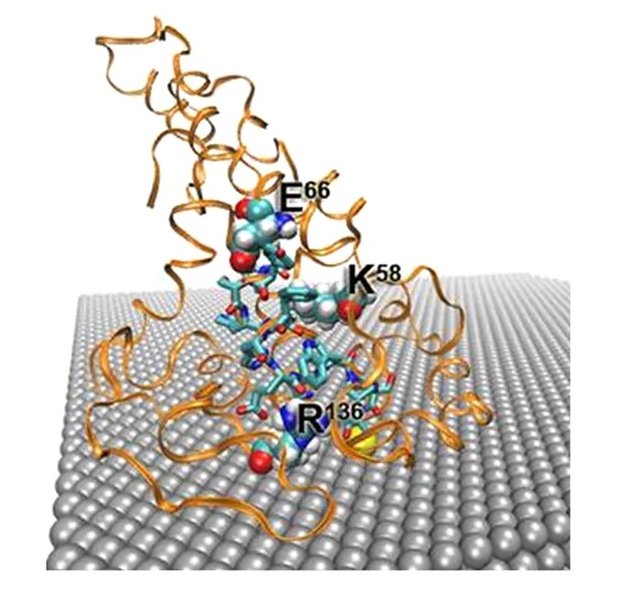
A peptide is designed for the recognition of graphene edges. Its functional mechanism is studied using molecular dynamics simulations. … Read more →
Peptide Functionalized Gold Nanorods for the Sensitive Detection of a Cardiac Biomarker Using Plasmonic Paper Devices
Scientific Reports. 2015
A peptide is characterized for the detection of Troponin I at physiological concentration. … Read more →
Biomimetic chemosensor: designing peptide recognition elements for surface functionalization of carbon nanotube field effect transistors
ACS Nano. 2010
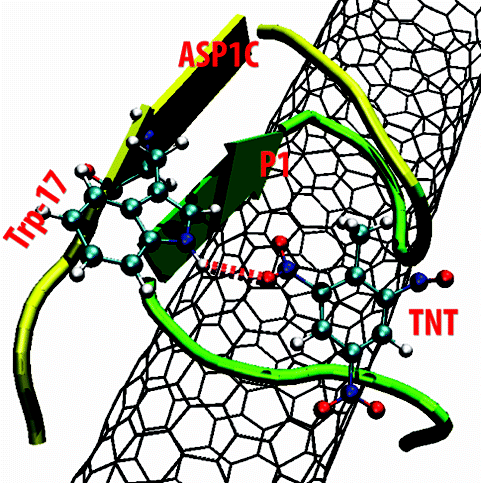
A hairpin bifunctional peptide is designed and characterized. One side anchors on a single-wall carbon nanotube. The other side binds to explosive TNT. … Read more →
Transpath: A computational method for locating ion transit pathways through membrane proteins
Proteins. 2007
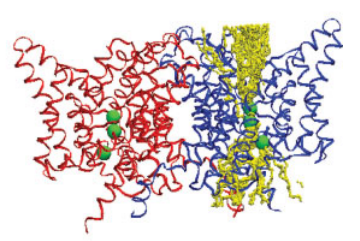
Here, we propose a new pore‐searching algorithm (TransPath), which uses the Configurational Bias Monte Carlo (CBMC) method to generate transmembrane trajectories driven by both geometric and electrostatic features. … Read more →
A Quantitative Analysis of the Feynman- and Rossi-Alpha Formulaswith Multiple Emission Sources
NUCLEAR SCIENCE AND ENGINEERING. 2000
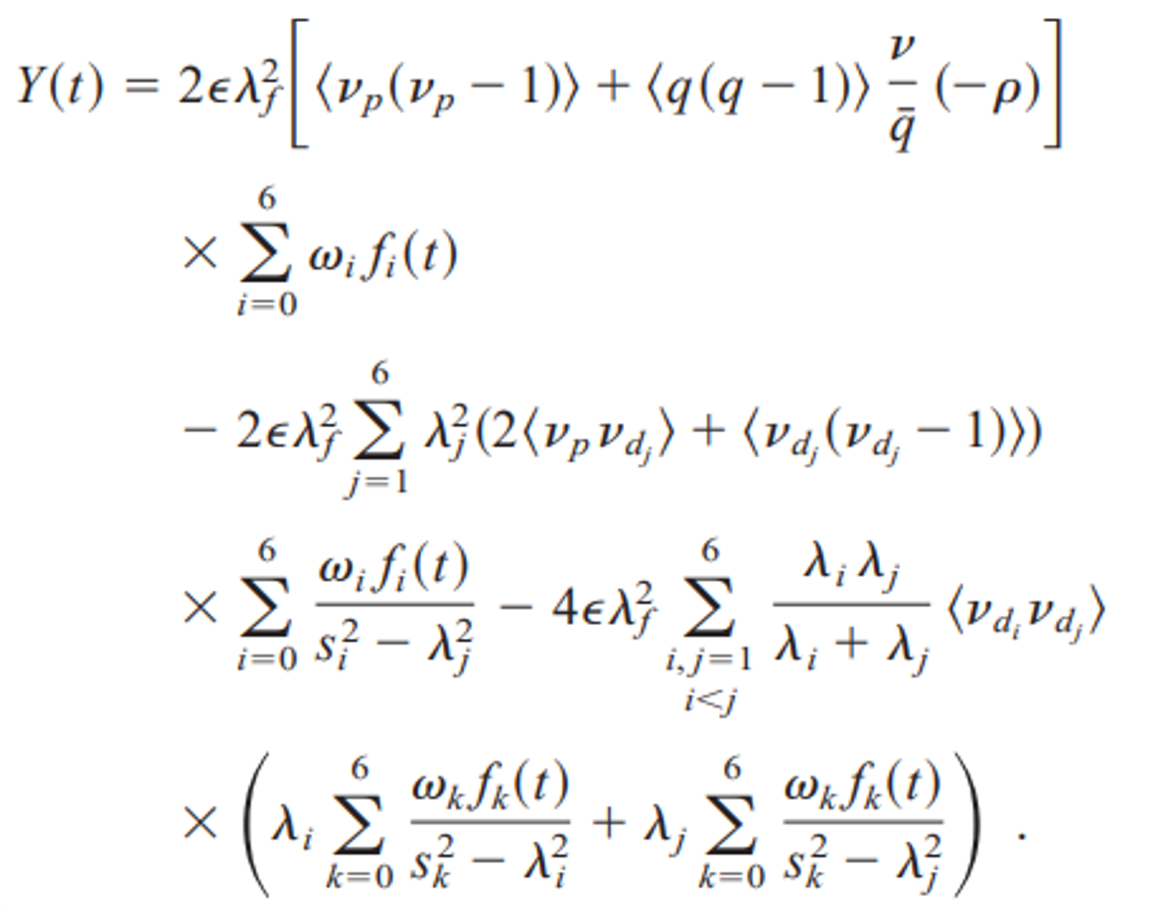
Analytical formulas have been derived for the Feynman- and Rossi-Alpha measurements in accelerator-driven systems. … Read more →
SPECTRUM OF THE TRANSPORT OPERATORIN A NONUNIFORM SLAB WITH GENERALIZEDBOUNDARY CONDITIONS
Transport Theory and Statistical Physics. 2002

Spectral properties of the transport operator in a nonuniform slab with generalized boundary conditions were studied. … Read more →